image by Taj Moore
This article describes a recipe that I would follow, in theory, when implementing the strangler pattern on a monolithic client-server application, such as might be found with a desktop application and database.
It is important to remember that each scenario is different and the method described here is more conceptual and not a specific example of a migration I have performed myself. However it outlines a set of phases that leaves both the monolithic application and any new systems in a state where value can be incrementally delivered without impacting existing workflows
Problem
There is a legacy monolithic client server application and I want to decompose it into microservices and deliver value incrementally.
Solution
The Strangler Fig Pattern offers a safe way to extract small pieces of the monolith into a new system.
The pattern can differ slightly depending on the architecture of the monolith and in this guide a monolith adopting a client-server architecture is described.
There are many challenges with client-server architecture, often direct access to the data is baked into the client through SQL queries or calls to stored procedures. It can be very challenging creating a layer of abstraction between the client and the data and refactoring the client might require further patterns of abstraction to handle this.
The goal here is to break down the process of getting through the strangler pattern while always having a state where value can be iterated on and delivered incrementally.
Assumptions:
Before getting started I will lay out some assumptions that have been made about the current architecture and the analysis that would have led us to the point of needing the Strangler Fig pattern.
In this solution we assume the majority of logic is in the client but the data is stored centrally and shared by other systems.
It is also assumed only the monolithic client writes data to the database and at least one read-only client exists to the data we want to strangle. This could be something as simple as a reporting tool or an ETL (Extract, Transform, Load) batch job.
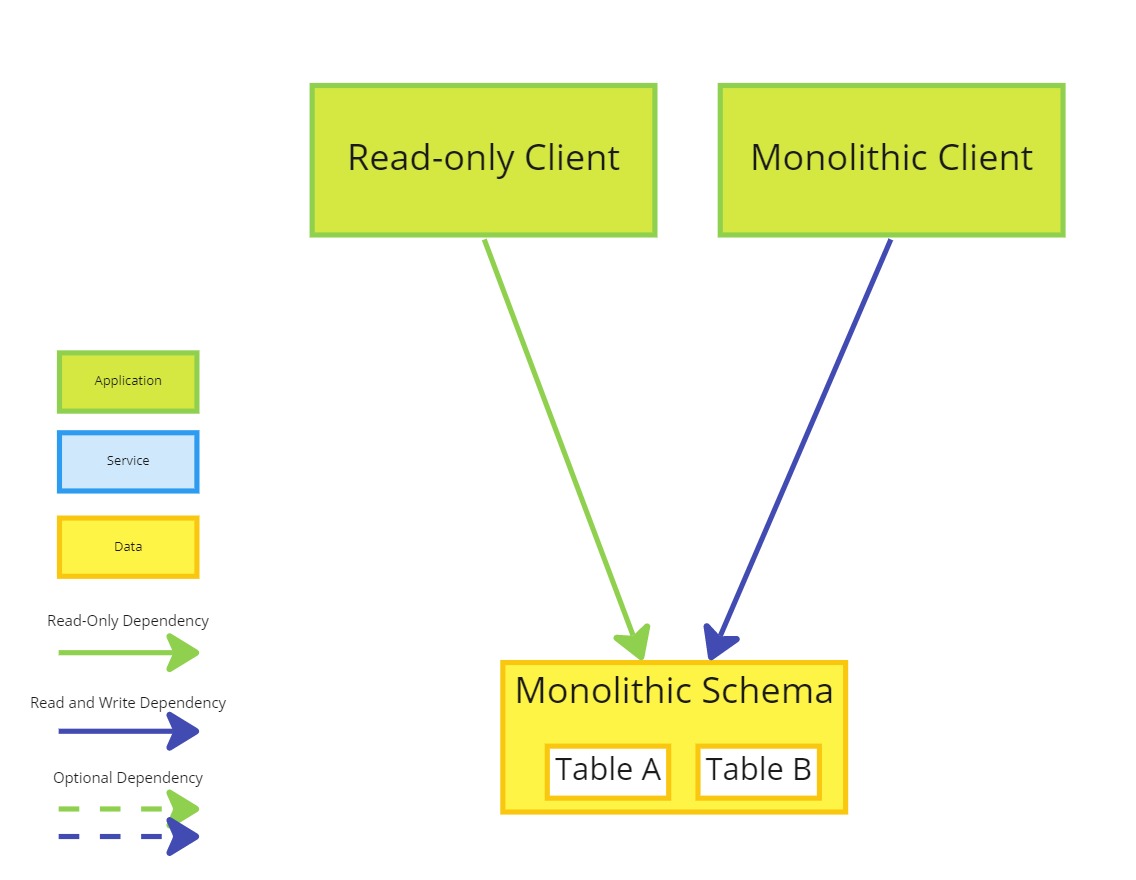
We also assume a piece of the monolith has already been identified as the first slice and a first iteration client has been designed.
It is also assumed there is sufficient means of testing both the monolith and new systems and there are already tests for the monolithic client that can be used to perform regression testing and to validate the new client and API.
How To
The following guide outlines an iterative approach to modernizing a monolithic system described as above
The guide outlines 4 conceptual phases that can be used to get from a monolith to a decoupled, microservice system:
- Strangle a New Client
- Parallelise Workloads
- Migrate to a New Schema
- Decouple Legacy Clients from the Monolithic Schema
1. Strangle a Client
The goal at this phase is to create an initial application that allows the delivery of value in the form of a new client, and begins a feedback loop to validate product assumptions.
This is also an opportunity to better explore the existing data and begin building a new schema
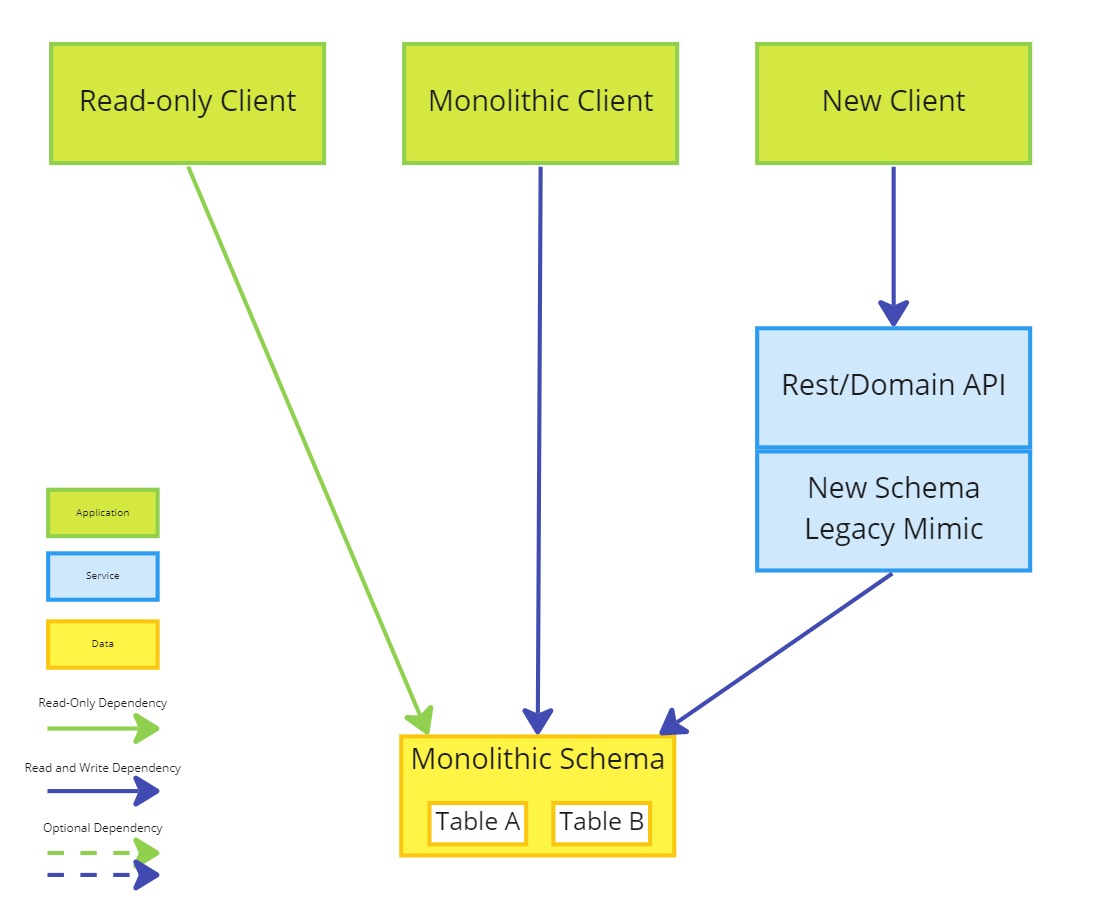
- Create a new client
- Create a new API to serve the new client
- Implement a legacy mimic to the monolithic schema
The legacy mimic should act as read and write access to the monolithic schema.
The monolithic client and read-only clients maintain their original access to the monolithic schema.
If the monolithic client can be easily refactored then it might be useful to modularise functionality or isolate views to data to remove circular references and decouple from other parts of the monolith
2. Parallelise Workloads
The goal of this phase is for the new client to decouple from the monolithic schema for any strangled data.
This should make it possible to implement isolated changes to either schema without impacting the other client.
The monolithic client shouldn't have changed and can still be used to validate the accuracy of the new system, ensuring data is correctly captured, calculated and stored.
Also a Parallel Run pattern can be adopted during this phase, to improve automated validation of the new system.
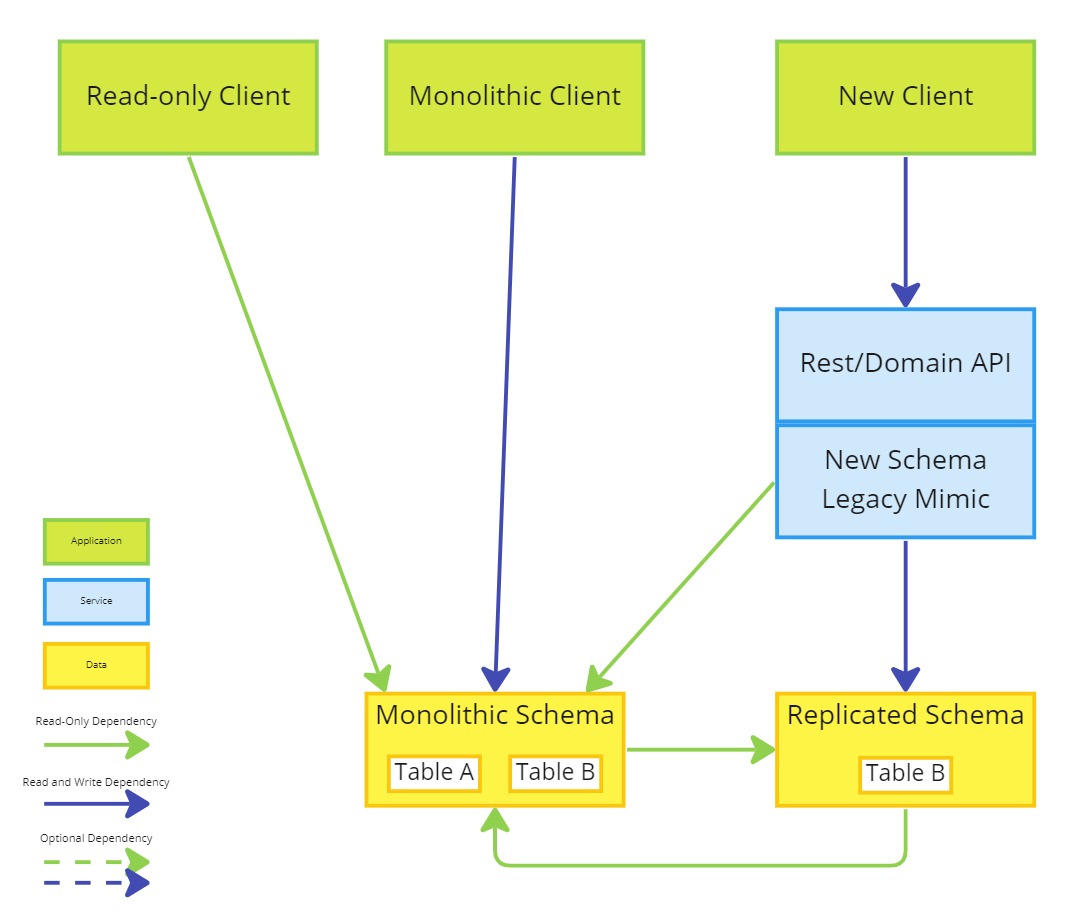
- Create a new schema, replicating the existing monolith
- Refactor the new schema legacy mimic to use the replicated schema
- Replicate from the monolithic schema to the replicated schema to achieve Event Interception
- Reverse Replicate from the replicated schema to the new schema to achieve Asset Capture
The Rest/Domain API might need to maintain read-only access to related or lookup data in the monolithic schema.
Two copies of Table B exist and updates to either should be replicated in the other to allow for the monolithic and new client to continue supporting the same workloads in parallel.
Replication between the two schemas would need to be carefully managed and orchestrated to avoid the pitfalls of reverse replication strategies.
The monolithic client and read-only clients remain unchanged and maintain their original access to the monolithic schema.
3. Migrate to a New Schema
The goal of this phase is to have migrated the replicated schema to a new schema that better serves the new system.
This phase can be completed in multiple steps, allowing for the further incremental change. However it is the final state of a complete migration that allows us to move on the next phase.
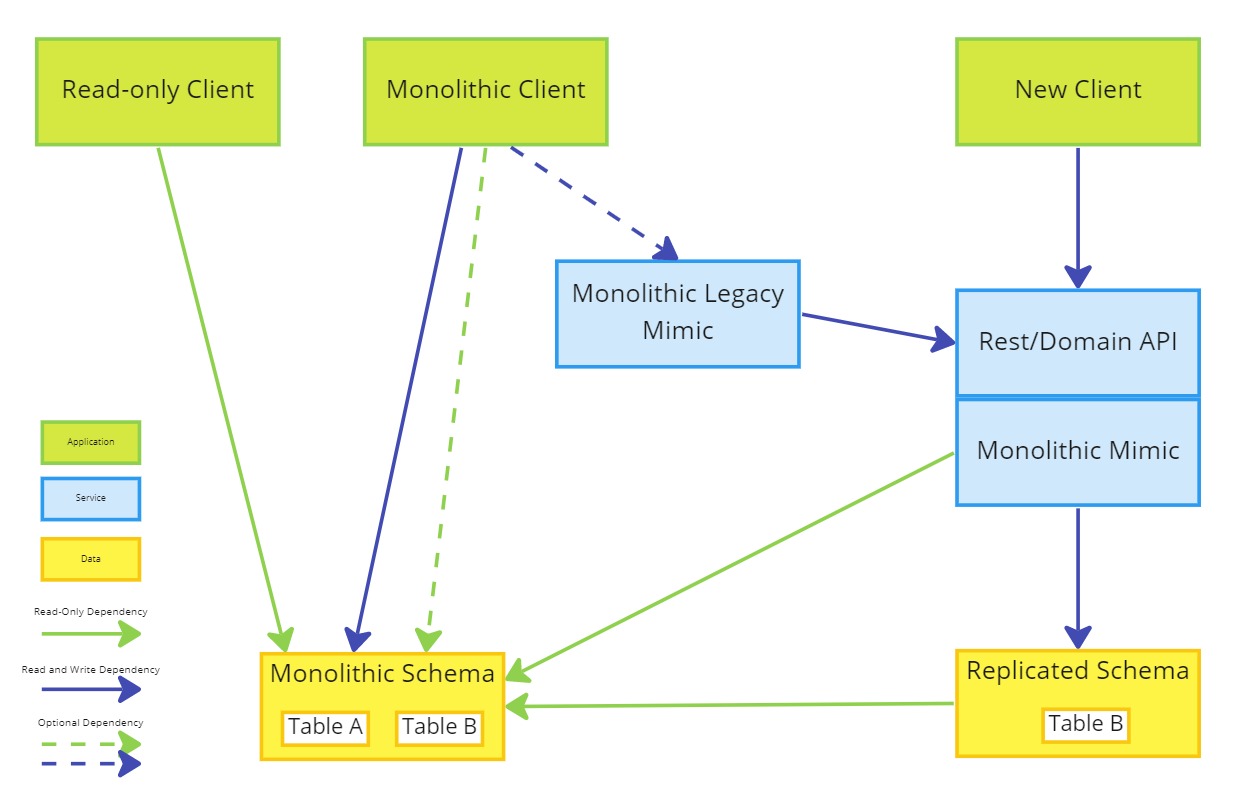
- Remove write access to the strangled data in the monolithic schema
- Refactor the monolithic client to use a legacy mimic or disable write functionality
- Remove Event Interception from the monolithic schema to the replicated schema
It is not always possible to refactor the monolithic client to use an API and so the only option might be to disable write functionality and require users move to the new client.
It should still be possible for the monolithic client to read the data replicated in the monolithic schema but it should not be possible to directly or indirectly, insert or update this data.
Replication from the Replicated Schema to the Monolithic Schema should be maintained to ensure read-only access to the monolithic schema.
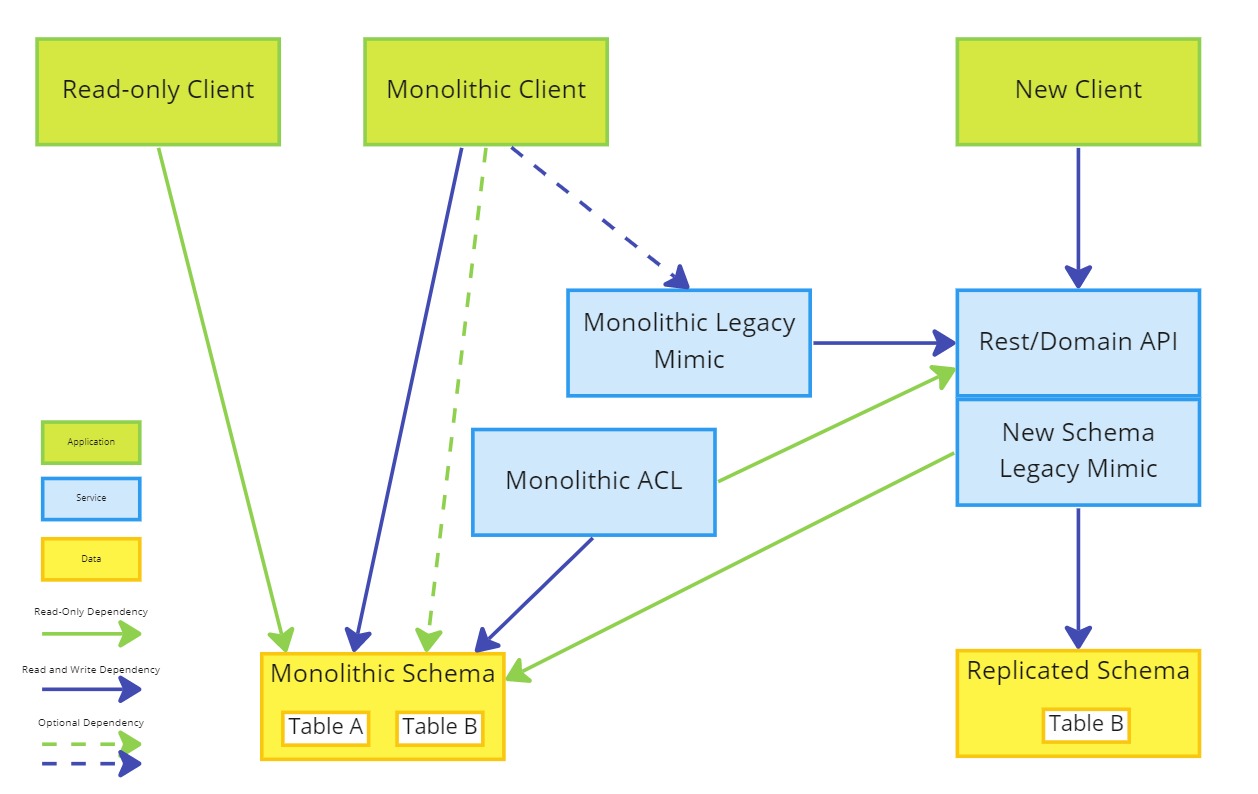
- Implement an anti-corruption layer between the Rest/Domain API and the Monolithic Schema
- Refactor replication and the monolithic client to use an Anti Corruption Layer
As the monolithic client no longer depends on the strangled data, an Anti-Corruption Layer should provide the mechanism for ensuring data consistency between the monolithic schema and the new system. The replication should be limited to only what is actually needed by other clients of the data.
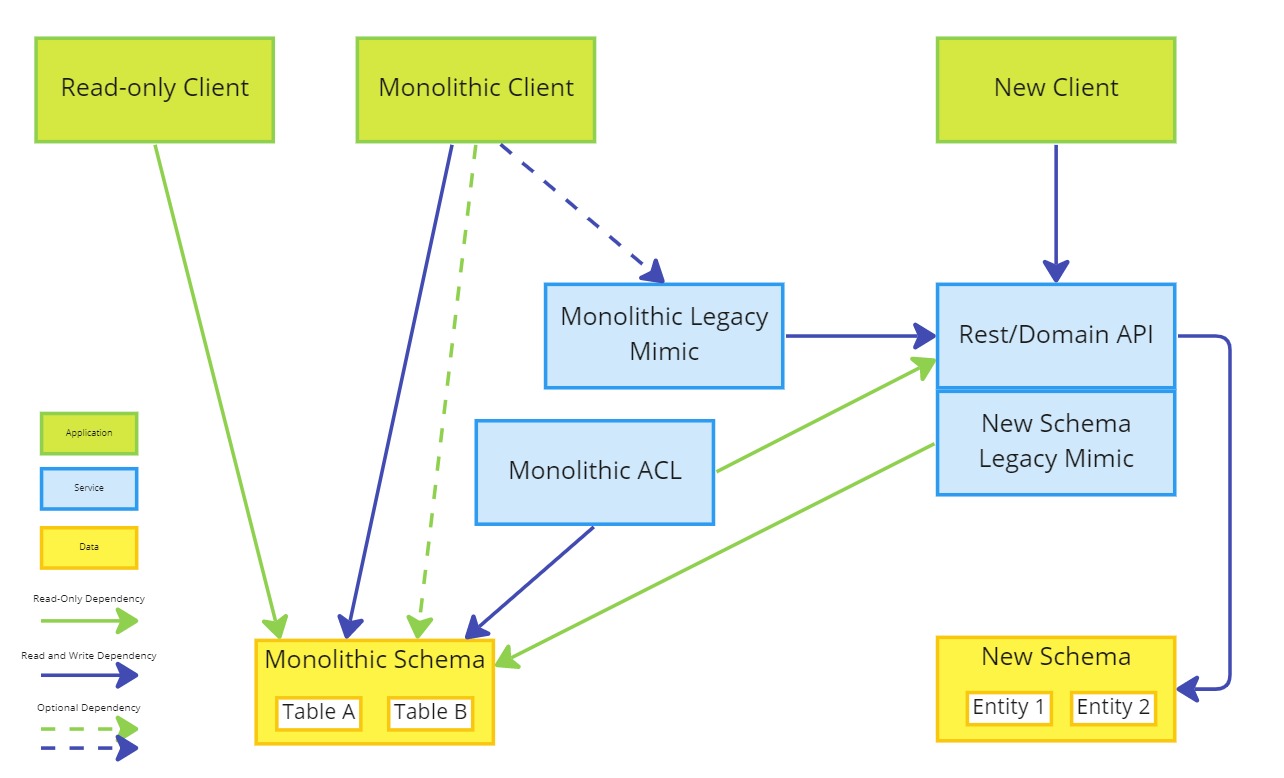
- Migrate the replicated schema into a new schema
- Refactor the Rest/Domain API to use the new schema directly
Migrating to the new schema should be a one-off task and marks the separation of the new system from the legacy.
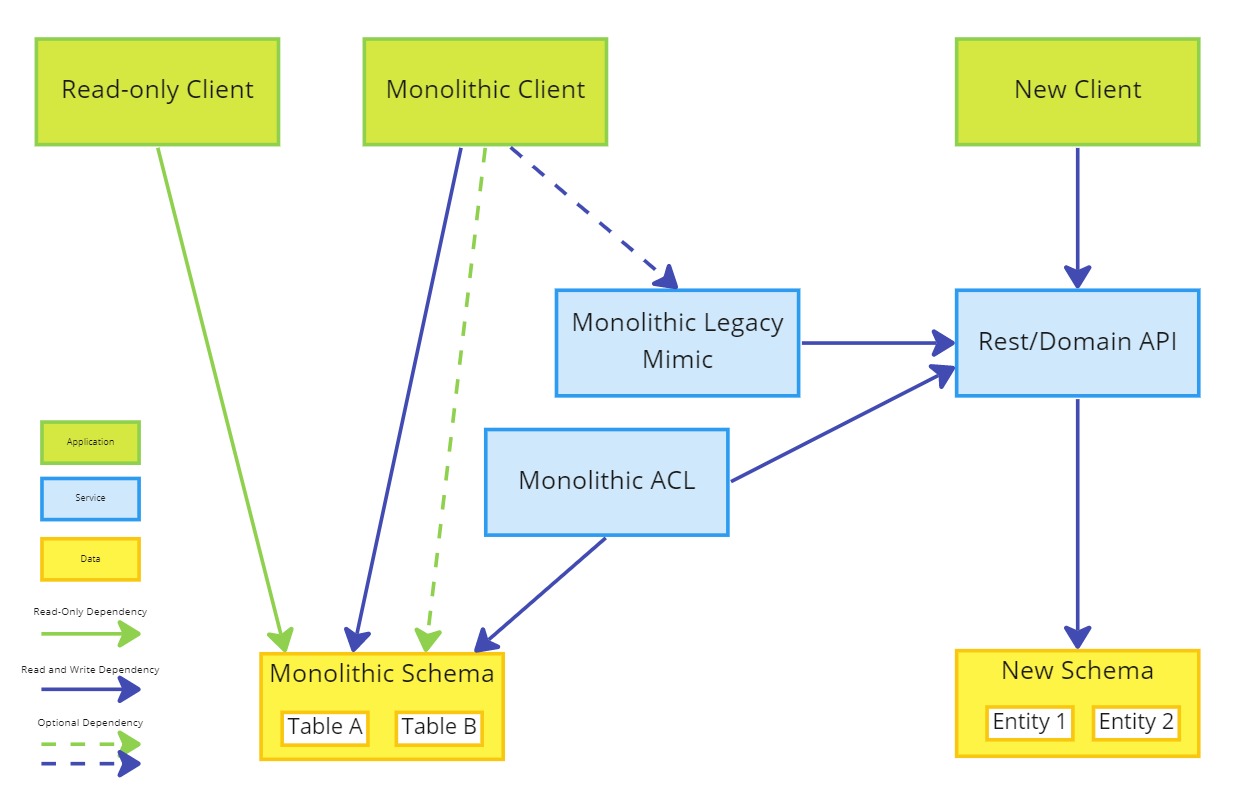
- Add read-only data to the new schema
- Implement replication of read-only data from the monolithic schema to the new rest/domain API
It is assumed that all data being read by the new schema legacy mimic is outside of the domain of the new system and so should be treated as read-only entities, and can be managed using the ACL during this phase.
4. Decouple Legacy Clients from the Monolithic Schema
The goal of this phase is to decouple everything else from the monolithic schema and remove the anti-corruption layer.
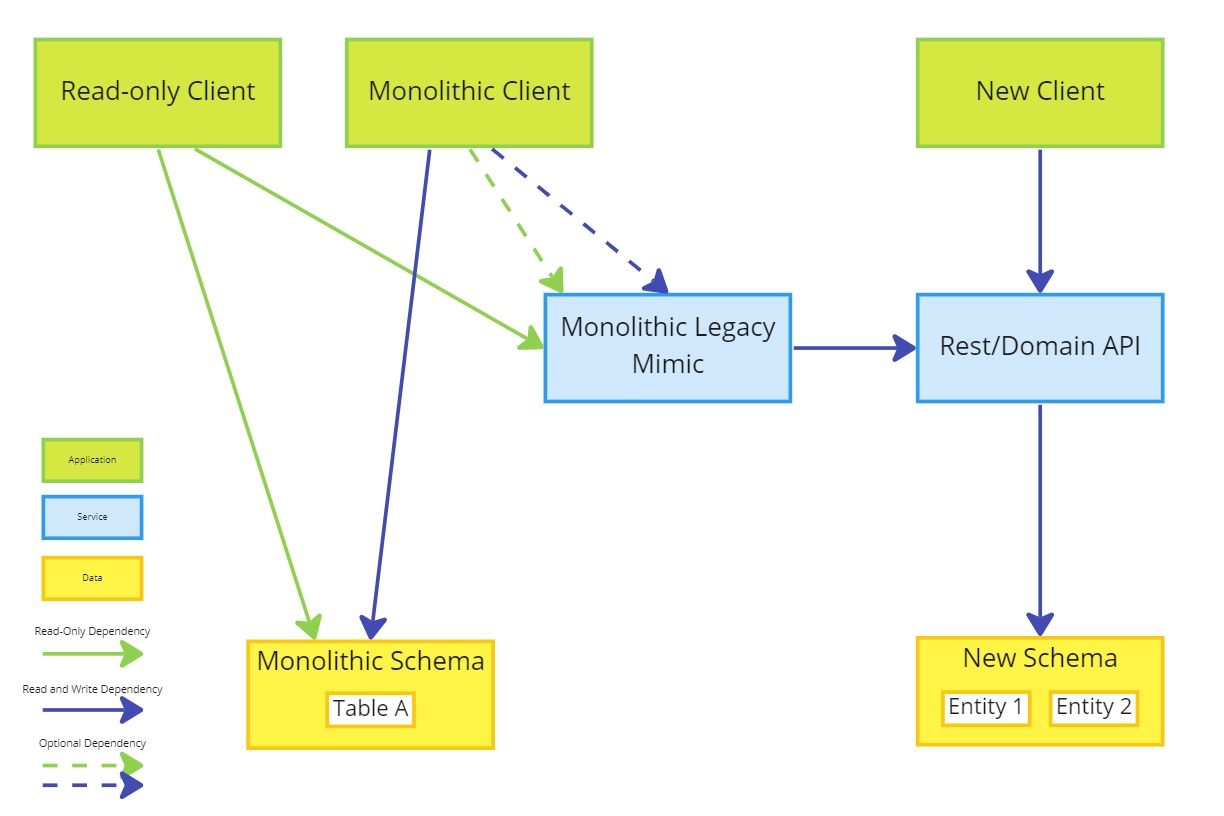
- Refactor the monolithic client and any read-only clients to use the monolithic legacy mimic
- Remove redundant tables and columns
- Remove all read dependencies from the new system to non strangled data in the monolithic schema
Decoupling read-only clients could require analysis over a long period of time to identify all clients to the data and safely move them to the monolithic legacy mimic.
The monolithic client and any read-only clients are refactored to decouple them from the monolithic schema, making the strangled data in the monolithic schema and the anti-corruption layer redundant allowing them to be removed.
If the monolithic client cannot be refactored to use a legacy mimic, this step might not be possible until these dependencies have been strangled or replaced and the anti-corruption layer becomes redundant.
Read-only clients could be handled by either retirement, replacement or refactoring to use a legacy mimic. In this example we assumed the read-only client can re-use the existing monolithic legacy mimic, however this may not always be true and a legacy mimic for each client might be preferred.
Notes
By the end of the final phase we should have successfully migrated a small part of the monolithic system into one or more microservices by achieving the following:
- Created a new client, a domain or restful API and data schema
- All redundant features in the monolithic client should have been removed
- Any active features of the monolithic client requiring access to the strangled data should have been strangled or refactored to use a legacy mimic
- All read-only clients should have been retired, replaced or refactored to use a legacy mimic
The strangler fig pattern can be difficult to implement in a client-server architecture particularly where the monolithic client has limitations to the way it can be refactored.
Data is often shared between domains within the monolith and to allow the monolithic client to continue to function normally during migration, access to that data will need to be resolved either through refactoring or an anti-corruption layer.
Each of the phases above should leave the system in a stable state that allows continuous migration and delivery of value, while maintaining existing quality and value.
It is important to bare in mind the work required to get to each phase may not be easy and could take time and collaboration between multiple teams to solve and implement.
The database technology serving the monolithic schema could be used to simplify the various stages and it is worth getting an expert to help with this and to analyse the data and activity on the monolithic schema to gain confidence in the new system.
It is also important to get an expert in the monolithic client technology to assist in this work, as there is a need to analyse and refactor the legacy client.
References
Strangler Fig Application by Martin Fowler
Event Interception by Martin Fowler
Asset Capture by Martin Fowler
Anti Corruption Layer by Microsoft
Monolith to Microservices by Sam Newman, O’Reilly Media, Inc
Lean Approach To Application Modernization by VMware Tanzu Labs
